

说起人工智能的文字生成,我们可以把它想象成一个非常特殊的打字机。传统的AI语言模型就像一个按部就班的打字员,必须一个字母一个字母地慢慢敲打,前面的字母没打完,后面的就得等着。但最近,上海交通大学和华为公司的研究团队开发出了一种全新的"打字方式",让AI能够同时敲打多个键盘,大大加快了文字生成的速度。
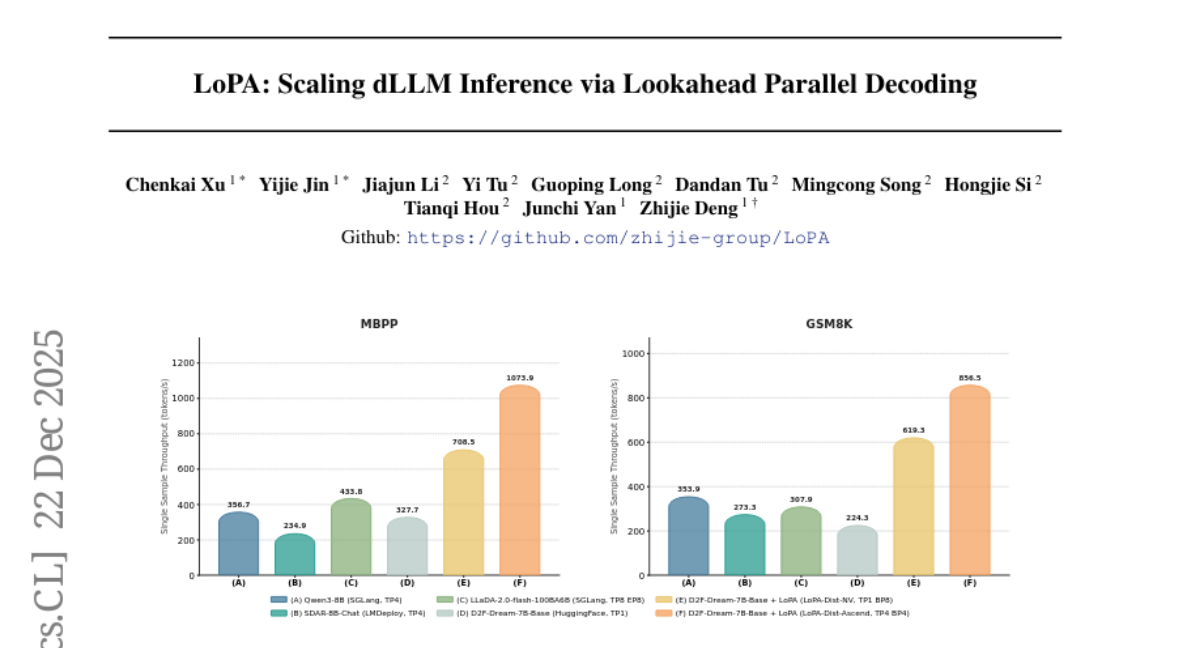
这项由上海交通大学严志杰教授领导,华为公司多名研究人员参与的研究发表于2025年12月,论文编号为arXiv:2512.16229v2。研究团队开发的技术叫做"LoPA"(Lookahead Parallel Decoding),简单来说就是"向前看的并行解码"技术。他们的方法成功让AI语言模型的推理速度提升了近10倍,在某些测试中达到了每秒生成1073个词汇的惊人速度。
要理解这项突破的重要性,我们需要先了解AI语言模型是如何工作的。就像厨师按照菜谱一步步做菜一样,传统的AI模型必须按顺序生成每一个词汇。当它要写"今天天气很好"这句话时,必须先确定"今天",然后才能考虑"天气",接着是"很",最后是"好"。这种串行的工作方式虽然准确,但速度相对较慢,特别是在处理长篇内容时。
近年来出现了一种新型的AI模型,叫做扩散大语言模型(dLLM)。这类模型的工作原理更像是艺术家创作一幅画——先有一个模糊的轮廓,然后逐步细化各个部分,最终得到完整的作品。在文字生成中,这意味着模型可以同时考虑句子中的多个位置,理论上能够并行生成多个词汇。
然而,扩散模型在实际应用中遇到了一个关键问题:虽然理论上可以并行工作,但由于置信度机制的限制,实际上每次前向传播只能确定1到3个词汇。这就像一个厨师虽然有多个炉灶,但因为对菜谱不够熟悉,每次只敢使用一个炉灶做菜,大大浪费了厨房的潜力。
研究团队通过深入分析发现,问题的根源在于"词汇填充顺序"(Token Filling Order)的选择。在扩散模型中,决定先填充哪个位置、后填充哪个位置,会显著影响模型的置信度分布。就像拼图游戏一样,如果你选择了错误的拼图策略——比如先拼边缘还是先拼中心——会直接影响后续步骤的难度和效率。
基于这个洞察,研究团队开发了LoPA技术。这个技术的核心思想非常巧妙:既然我们无法提前知道哪种填充顺序最好,那就同时尝试多种可能的顺序,然后选择最有潜力的那一个。
具体来说,LoPA的工作过程可以比作一个经验丰富的象棋大师在下棋时的思考过程。当面临一个复杂局面时,大师不会只考虑一种走法,而是会在脑海中同时模拟多种可能的走法,预测每种走法可能导致的后续局面,然后选择最有希望获胜的那一步。
LoPA技术分为三个阶段。首先是"分支准备阶段",系统会基于当前的文本状态,创建一个主要分支和多个探索分支。主要分支采用传统的置信度驱动策略,而探索分支则会尝试不同的词汇填充顺序。这就像一个导航系统同时规划多条可能的路线。
接下来是"并行验证阶段",系统会同时评估所有分支的可行性。这个过程非常高效,因为所有分支可以在一次前向传播中同时处理,就像一台超级计算机同时运行多个模拟程序。
最后是"最优选择阶段",系统会根据每个分支的"未来并行化潜力"来选择最佳路径。这个评估标准非常聪明:它不仅考虑当前步骤的质量,更重要的是预测选择这个分支后,在下一步能够并行处理多少个词汇。
研究团队将LoPA技术应用到了D2F模型上,这是目前最先进的扩散大语言模型之一。实验结果令人印象深刻:在数学问题求解任务(GSM8K)上,LoPA将模型的并行度提升到10.1,也就是说每次前向传播能够确定超过10个词汇,比传统方法提升了3倍以上。在代码生成任务(HumanEval+)上,并行度达到了8.3,同样实现了显著提升。
更重要的是,这种速度提升并没有牺牲生成质量。在保持与原始模型相当甚至更好的准确率的同时,LoPA实现了大幅度的加速。这就像找到了一种既快又好的新烹饪方法,既节省时间又保证了菜品质量。
为了将算法上的改进转化为实际的系统性能提升,研究团队还开发了专门的分布式推理系统,叫做"LoPA-Dist"。这个系统引入了"分支并行"(Branch Parallelism)的概念,将不同的探索分支分配给不同的计算设备,实现真正的并行计算。
LoPA-Dist系统有两个版本:针对英伟达CUDA平台优化的LoPA-Dist-NV和针对华为昇腾910C芯片优化的LoPA-Dist-Ascend。两个版本都实现了接近线性的扩展性,也就是说使用的计算设备越多,性能提升越明显。
在华为昇腾平台上,LoPA-Dist-Ascend达到了单样本每秒1073.9个词汇的惊人吞吐量。要知道,人类的正常阅读速度大约是每分钟200-300个词,这意味着这个AI系统的文本生成速度比人类阅读速度快了十几倍。
系统设计中最巧妙的部分是KV缓存管理协议。在传统的语言模型中,为了避免重复计算,系统会缓存之前计算的中间结果。但在LoPA的多分支架构中,不同分支会产生不同的缓存状态,如何保持一致性成了技术难点。研究团队设计了两阶段更新机制:先让各个设备预写入自己的缓存,然后在确定最优分支后,将获胜分支的缓存广播到所有设备,确保全局一致性。
研究团队在多个标准测试集上验证了LoPA的效果。在数学推理任务上,LoPA不仅大幅提升了速度,还略微改善了准确率。在代码生成任务上,速度提升同样显著,而准确率基本保持不变。这证明了LoPA是一个真正意义上的"免费午餐"——既快又好。
特别值得注意的是,LoPA技术具有很强的通用性。研究团队证明,这个技术不仅适用于D2F模型,也可以轻松集成到其他基于置信度驱动的扩散语言模型中,是一个真正的"即插即用"解决方案。
从技术角度来看,LoPA的创新在于它改变了我们对并行化的思考方式。传统的方法试图在固定的生成策略下挤压更多的并行性,而LoPA则从根本上质疑了生成策略的选择,通过动态优化策略来释放更多的并行化潜力。
对于普通用户来说,这项技术的应用前景非常广阔。更快的语言模型意味着更流畅的AI对话体验,更高效的文档生成,以及更实时的翻译服务。当AI助手能够几乎瞬间理解并回应用户的复杂请求时,人机交互的体验将发生质的飞跃。
对于企业和开发者来说,LoPA技术意味着可以用更少的计算资源提供更好的AI服务。这不仅降低了运营成本,也让高质量的AI服务更加普及和可及。
研究团队的工作还展现了学术界与产业界合作的典型成功案例。上海交通大学提供了理论创新和算法设计,华为公司贡献了工程实现和系统优化经验,双方的结合产生了既有理论深度又有实用价值的研究成果。
展望未来,LoPA技术开启了扩散语言模型优化的新方向。研究团队在论文中指出,除了分支置信度之外,还可以探索其他的分支选择标准,比如考虑输出多样性、稳定性等因素。此外,LoPA的思想也可能启发其他类型AI模型的优化工作。
这项研究的另一个重要意义在于它证明了在AI大模型时代,算法创新仍然具有巨大的价值。虽然现在的趋势是通过增加模型规模和计算资源来提升性能,但LoPA展示了聪明的算法设计同样能够带来显著的性能突破,而且往往更加经济和环保。
说到底,LoPA技术就像给AI语言模型装上了一个"智能大脑",让它能够同时思考多种可能性,选择最优的生成策略。这不仅大大提升了AI的工作效率,也为我们展示了人工智能优化的新可能性。随着这类技术的不断发展和完善,我们有理由期待一个更加智能、高效的AI时代的到来。
Q&A
Q1:LoPA技术具体是什么?
A:LoPA是"向前看的并行解码"技术,由上海交通大学和华为联合开发。它让AI语言模型能够同时尝试多种不同的词汇生成顺序,然后选择最有效率的那一种,从而大幅提升文本生成速度,最高可达每秒1073个词汇。
Q2:LoPA技术会影响AI生成内容的质量吗?
A:不会。实验结果显示,LoPA在大幅提升生成速度的同时,还能保持甚至略微改善生成质量。在数学推理和代码生成等任务上,准确率都与原始模型相当或更好,实现了速度和质量的双重提升。
Q3:普通用户什么时候能体验到LoPA技术?
A:LoPA是一个即插即用的技术,可以轻松集成到现有的AI语言模型中。随着技术的进一步成熟和推广,预计很快就能在各种AI助手、翻译工具和文档生成服务中体验到更快更流畅的AI响应。
富灯网提示:文章来自网络,不代表本站观点。


